2025我的ai总结
我关于 2025 AI 的总结
2025 年一整年我都在折腾 AI 相关的项目,不管是研究 Agent 的底层架构,还是自己动手写代码、调接口,基本每天都在跟各类大模型(LLM)打交道。
本来想着现在已经是 2026 年初了,刚好抽空把去年积攒的一些关于 LLM 的开发经验和“最佳实践”总结一下,算是给自己的 2025 做个复盘。但真到了提笔的时候才发现:技术的迭代实在太快,我大半年前奉为圭臬的一些经验,放到现在居然已经不适用,甚至显得有些多余了。
借着这个机会,随便聊聊这一年里我对“怎么用好 AI”这件事的认知转变。
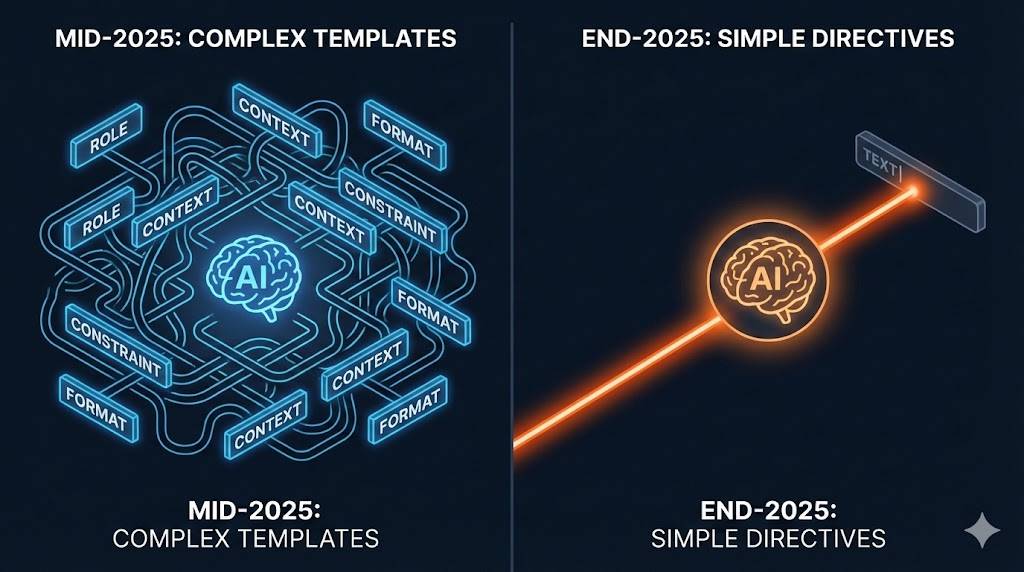
曾经被神化的提示词模版
如果在 25 年中的时候来问我,我会告诉你:要让 LLM 干好活,必须得写好提示词(Prompt),而且最好用一套结构化的模版。
那时候大家都在卷 Prompt Engineering。我也跟着套用了不少模版,每次给模型下指令,都要老老实实地按照 Role(角色设定)、Task(任务)、Context(背景)、Constraint(约束条件)这些维度去填空。起手式永远是“你现在是一个拥有 20 年经验的资深开发专家……深呼吸,慢慢想”。
当时觉得这种做法很专业,也确实能在一定程度上把模型拉到我想要的语境里。
模版正在变成累赘
但到了 25 年底,我在实际敲代码和跑测试的时候发现情况变了。
懒得去套长篇大论的模版时,直接把报错日志或者需求大白话甩给它,结果模型给出的反馈不仅没有变差,反而跟精心构造的模版效果一样好,甚至更好。
反过来看,以前那些复杂的提示词模版,缺点开始暴露无遗:太复杂,且有效信息被隐藏。
一个模版里充斥着大量的格式要求和背景废话,这会导致真正有价值的核心信息(比如具体的业务逻辑、关键的上下文)被淹没。模型去处理这些外围的条条框框,反而抓不住你要解决的核心问题。
一个打破认知的“卡 Bug”实验
最近 Google Research 的一项研究,完美印证了我这个想法。
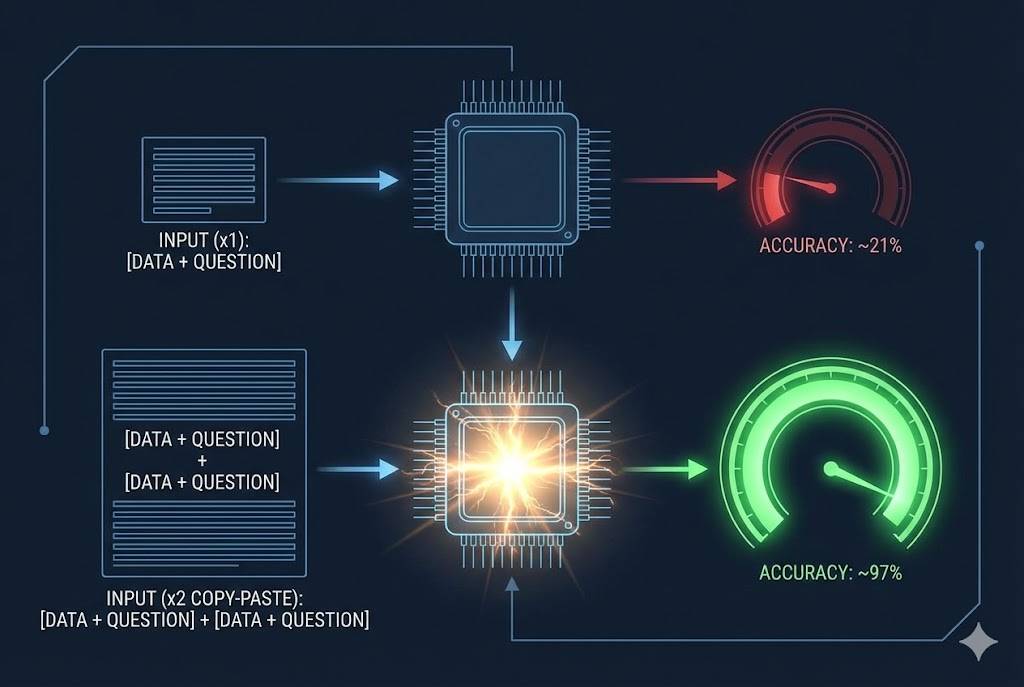
他们发现,对于一些非推理的大模型,想让它在长文本里找答案更准确,根本不需要什么复杂的角色设定,只需要做一件极其粗暴的事:把问题复制粘贴,连着问两遍。
比如在一个寻找特定信息的任务里,单次提问的准确率只有 21.33%,但只要你把 [资料+问题] 复制一遍变成 [资料+问题] + [资料+问题],准确率直接飙升到了 97.33%。
这听起来像是在卡 Bug,但其实暴露了大模型的底层逻辑。大模型是一路从左往右读的,当你塞给它一大堆 Role、Background 废话时,它读到最后早就把前面的核心问题忘了。而重复一遍问题,或者干脆只抛出最关键的信息,等于是强行把它的注意力死死钉在关键点上。
所以,现在的我得出一个结论:跟大模型沟通,越简单的提示词才是最优解。 剔除掉所有不影响逻辑的废话,直接下达指令。
从强编排到自动编排
除了写提示词的方式变了,这一年里,AI 应用架构的演进也发生了极大的转变。最明显的就是从 Workflow(工作流)向 Agent Skills(智能体技能)的进化。
25 年中的时候,做复杂的 AI 应用往往要依赖 Workflow 的强编排。你需要像画流程图一样,预先把所有的条件分支写死:如果 A 节点输出 X,就走 B 节点;如果输出 Y,就走 C 节点。这其实还是传统的写代码思维。
但现在,这种生硬的强编排正在被 Agent Skills 的自动编排所取代。你不再需要去定义死板的流转路线,而是给 LLM 提供一堆 Skills(技能工具),让大模型自己根据当前的用户意图,去决定调用哪个技能、传递什么参数。
如果你再深入一点去拆解这些市面上流行的 Agent 框架,你会发现所谓的 Skills,不过就是一堆 .md 文件的组合。里面用文本写着这个工具叫什么名字、干什么用的、参数是什么。
再往深想一步,既然只是文本描述,那我们做企业级应用的时候,就一定非得基于 .md 文件来构建 Skills 吗?显然不是。
这些技能的配置完全可以(也更应该)存储在数据库里面。作为开发者,我们真正要关心的,根本不是 有没有 skill.md文件 ,而是它的底层流转机制:如何把你的 Skill 存起来,如何技能库中检索和选择出最合适的,如何高效加载,以及最后如何干净利落地把它交给 LLM 去使用。

所谓学其意不学其形。做 AI 开发也是一样,别被外面那些花哨名字给框住了。把复杂的概念剥开,留下最简单直接的信息流转,往往就是现阶段最稳妥、最高效的解法。