从提示词工程到上下文工程
提示词工程与上下文工程
在人工智能迅猛发展的今天,我们与大型语言模型(LLM)的互动方式正在经历一场深刻的变革。最初,我们依赖于“提示词工程”(Prompt Engineering)——一种通过精心设计问题来引导模型输出期望答案的艺术。然而,随着AI应用日益复杂,我们发现,仅仅优化提问方式已不足以应对挑战。一个更宏大、更具系统性的概念——“上下文工程”(Context Engineering)——正逐渐成为构建更强大、更智能AI系统的核心。
从提示到上下文:一场思维的跃迁

长久以来,开发者们致力于寻找最巧妙的词语组合,以期“诱导”AI给出更精准的回答。这在简单的问答场景中确实行之有效。但当任务变得复杂,例如需要处理多轮对话、调用外部工具或参考历史信息时,单纯的提示词就显得力不从心了。
问题的根源在于,大型语言模型本身并不具备真正的“理解力”或“记忆力”。它们更像一个信息处理引擎,其输出质量高度依赖于我们输入信息的质量。如果模型缺乏必要的背景信息(即“上下文”),或者这些信息的组织方式混乱,那么即使再完美的提问也难以得到满意的结果。这就好比要求一位大厨在没有食材和厨具的情况下做出一道美味佳肴,是强人所难。
什么是上下文工程?
“上下文工程”正是为了解决这一问题而生。它不再局限于单一的提问技巧,而是着眼于构建一个动态的、系统化的信息供给机制。其核心目标是:在合适的时机,以合适的格式,为大型语言模型提供完成任务所需的一切准确信息和工具。
我们可以从以下几个维度来理解上下文工程:
| 核心要素 | 描述 |
|---|---|
| 系统性 | 一个复杂的AI应用可能需要整合来自不同来源的信息,包括用户的即时输入、历史对话记录、外部数据库、API调用结果等。上下文工程需要将这些零散的信息整合成一个连贯、有序的整体。 |
| 动态性 | 上下文信息并非一成不变,而是随着交互的进行而动态变化的。因此,构建最终提示的逻辑也必须是动态的,能够根据当前情况灵活调整,而非套用静态模板。 |
| 准确性 | “垃圾进,垃圾出”是信息处理的铁律。为模型提供准确、无误的信息是保证其输出质量的根本前提。 |
| 工具赋能 | 很多时候,仅凭已有信息无法完成任务。此时,我们需要为模型配备合适的“工具”,例如信息检索工具、计算器、代码执行器等,并教会它如何使用这些工具来获取更多信息或执行特定操作。 |
| 格式规范 | 信息传递的方式与其内容同等重要。我们需要将各种信息和工具指令以一种模型最容易理解的、结构化的方式呈现给它,从而最大限度地降低沟通成本。 |
上下文工程与提示词工程的关系
那么,上下文工程的兴起是否意味着提示词工程的终结?答案是否定的。
更准确地说,提示词工程是上下文工程的一个重要子集。无论我们拥有多么丰富和准确的上下文信息,最终都需要通过一个精心组织的“提示”来将其呈现给模型。优秀的提示词工程技巧,例如清晰地阐述指令、定义角色和目标,在上下文工程中依然至关重要。
二者的区别在于,上下文工程将我们的视角从“如何更好地提问”提升到了“如何更好地供给信息”的战略高度。它要求我们不再仅仅是一个“提问者”,更要成为一个“系统架构师”,为AI智能体构建一个强大的信息支撑系统。
构建卓越上下文工程的要素
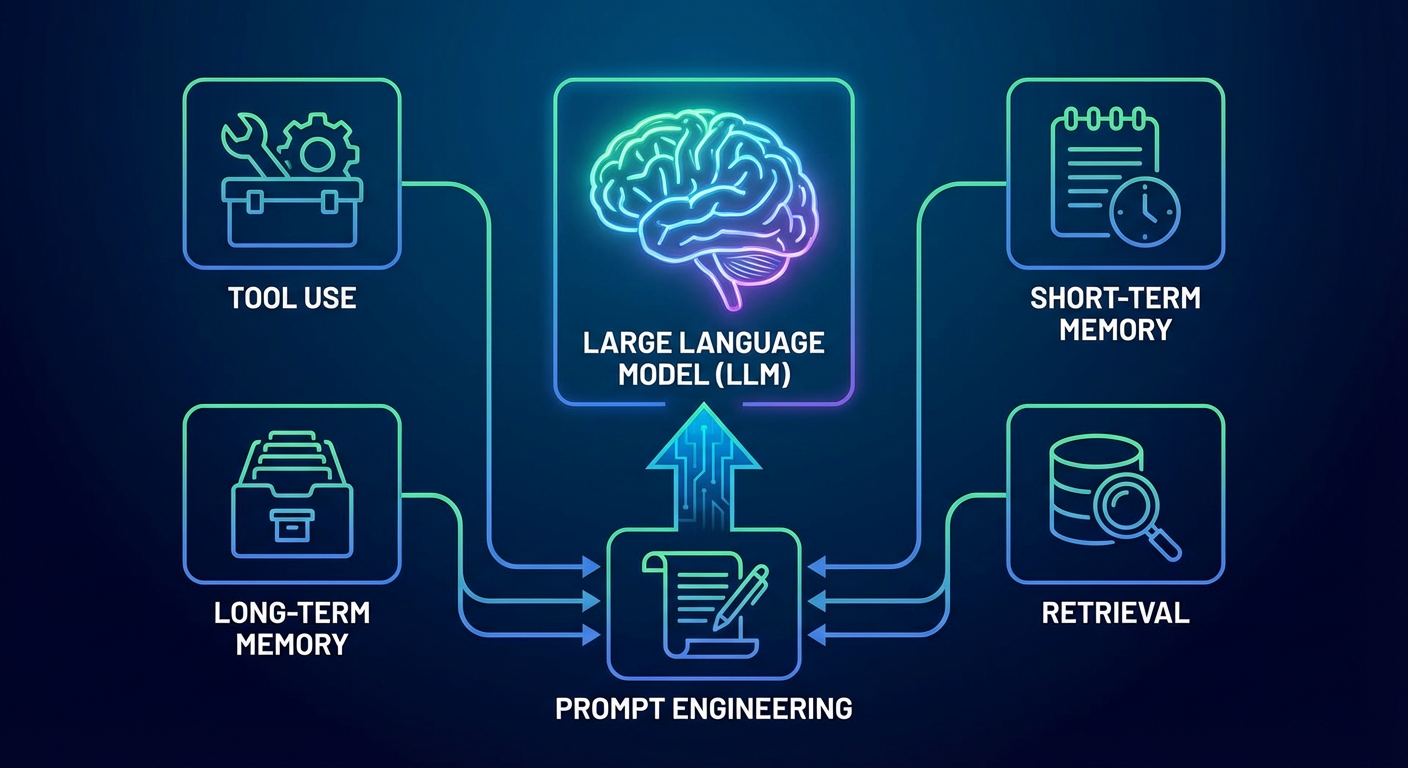
一个完善的上下文工程系统通常包含以下几个关键组成部分:
- 工具使用 (Tool Use): 赋予模型访问和使用外部工具的能力,并通过结构化的格式反馈工具的执行结果。
- 短期记忆 (Short-term Memory): 对于持续进行的对话,通过生成对话摘要等方式,保留近期的关键信息。
- 长期记忆 (Long-term Memory): 记录用户在过往交互中表达的偏好、习惯等信息,并在需要时调取。
- 检索 (Retrieval): 从外部知识库或数据库中动态地获取相关信息,并将其整合到上下文中。
- 提示工程 (Prompt Engineering): 将以上所有信息以清晰、明确、结构化的方式组织在最终的提示中。
总之,从提示词工程到上下文工程的演进,标志着AI应用开发范式的重大转变。未来,AI工程师的核心竞争力将不再仅仅是写出漂亮的提示词,更是构建复杂、动态、高效的上下文供给系统的能力。只有掌握了上下文工程,我们才能真正释放大型语言模型的巨大潜力,构建出更加智能、可靠的AI应用。